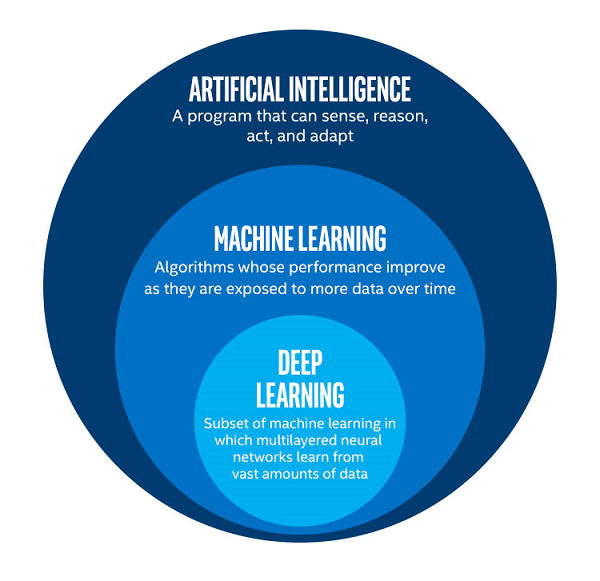
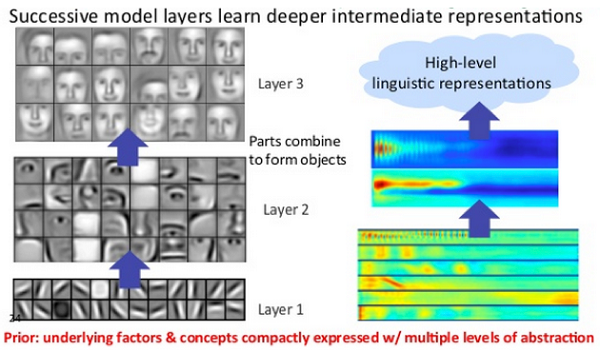
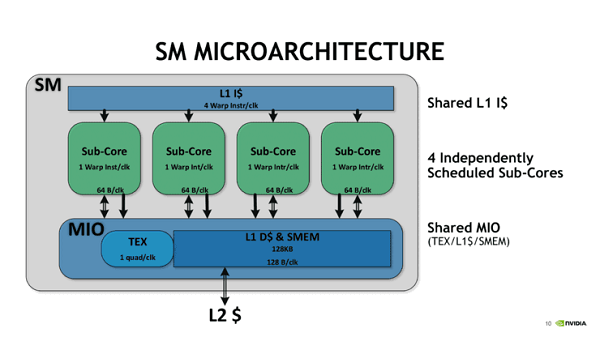
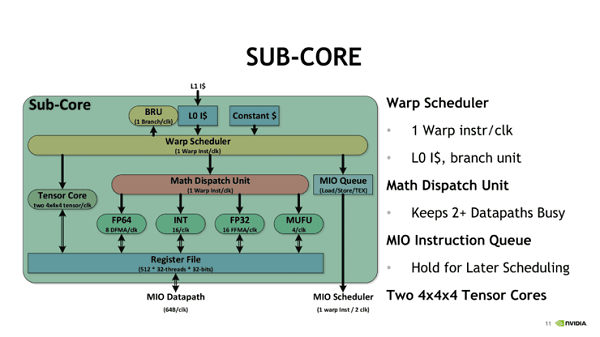
Turing architecture-based NVIDIA Quadro RTX should be the best deep learning GPU







![]()

















OpenAI is nothing without its people
We remain committed to our partnership with OpenAI and have confidence in our product roadmap, our ability to continue to innovate with everything we announced at Microsoft Ignite, and in continuing to support our customers and partners. We look forward to getting to know Emmett…
Revamp your style with our GPT tool! Get personalized fashion tips for any occasion and trend. Easy, trendy, transformative – try it now! #StyleSage #FashionGPT
Leveraging Dr. Berg's extensive knowledge base, we have meticulously crafted an advanced GPT model. This tool quickly retrieves and provides various health and nutrition knowledge shared by Dr. Berg.
Here are a few GPTs that I personally feel are very powerful.
A thread