
Latest technology in Artificial Intelligence you need to know
by Ready For AI · July 23, 2018
Introduce the latest technology in artificial intelligence, and combine the status quo to make some personal judgments on the future development trend.

From AlphaGo Zero to Alpha Zero: A key step towards universal artificial intelligence
In 2017, AlphaGo Zero made a further technical upgrade as the second generation of AlphaGo. It is extremely easy to defeat the AlphaGo generation. This shows that human beings are not qualified to compete with artificial intelligence in Go. AlphaGo’s general-purpose version of Alpha Zero was released at the end of 2017. Not only is Go, but for other chess games such as chess and Japanese chess, Alpha Zero also overwhelmingly defeated the most powerful AI program including AlphaGo Zero.
AlphaGo Zero has not been substantially improved in terms of technical means compared with AlphaGo. The main body is still the structure of MCST Monte Carlo search tree plus neural network and deep-enhanced learning training method, but the technical implementation is simple and elegant (refer to the picture below) .
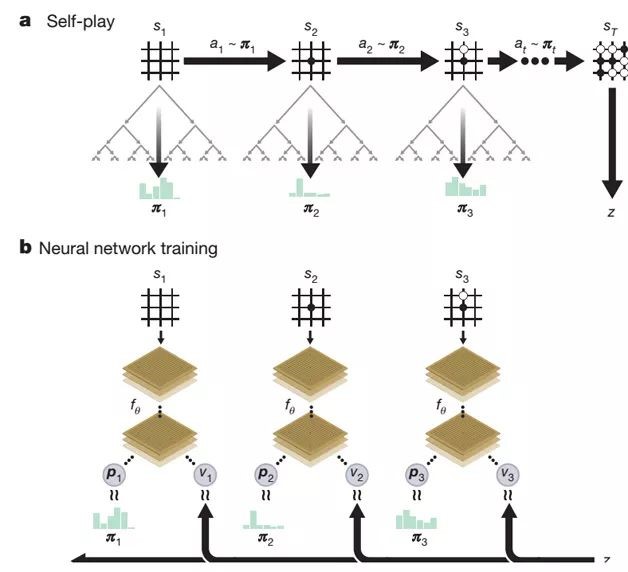
The main changes consist of two things:
- One is to merge AlphaGo's two predictive networks (strategic and value networks) into one network, but at the same time produce two types of required outputs;
- The second is the upgrade of the network structure from CNN structure to ResNet.
From AlphaGo’s one-step stepping strategy, DeepMind is considering the versatility of this extended technology solution, enabling it to solve more problems with a set of technologies, especially those that are of real value in non-gaming real life. problem. At the same time, AlphaGo series technology also showed the power of deep-enhanced learning to machine learning practitioners, and further promoted relevant technological advances. At present, we can also see examples of deep-enhanced learning applied in more fields.
GAN: The prospects are broad, and the theory and application are developing rapidly.
GAN, known as Generative Adversarial Nets. As a representative of the generation model, GAN has attracted widespread attention from the industry since it was proposed by Ian Goodfellow in 2014. Yann LeCun, one of the deep learning masters, highly praised GAN, which is the most interesting machine learning industry in the past decade. Thoughts.
GAN has a wide range of application scenarios, such as image style conversion, super-resolution image construction, automatic black-and-white image coloring, image entity attribute editing (such as automatically adding a beard to the portrait, switching the color of the hair and other attributes), between different areas of the picture Conversion (for example, the spring image of the same scene is automatically converted to a fall image, or the daytime scene is automatically converted to a nighttime scene), or even the dynamic replacement of the image entity, such as changing a cat in a picture or video into a dog (Refer to the picture below).

In the past, there has been good progress in how to increase the stability of GAN training and solve the collapse of the model. GAN essentially uses the generator and discriminator to conduct confrontation training. The forced generator does not know the true distribution Pdata of a certain data set, and adjusts the distribution Pθ of the generated data to fit the real data distribution Pdata. It is critical to calculate the distance metrics for the two distributions Pdata and Pθ during the current training process.
Capsule: Expect to replace CNN's new structure
The Capsule structure was published in the form of a thesis in the form of a essay in the form of “Deep Learning Godfather” by Mr. Hinton, and the paper became the focus of researchers’ attention, but in fact, this thought Hinton has been thinking deeply for a long time and before on various occasions. Propaganda this idea. Hinton has always been very interested in the Pooling operation in CNN. He once said: “The Pooling operation used in CNN is a big mistake. In fact, it works well in actual use, but it is actually a disaster.” So what is the problem with MaxPooling that makes Hinton hate it? The reason can be seen by referring to the example shown in the picture below.
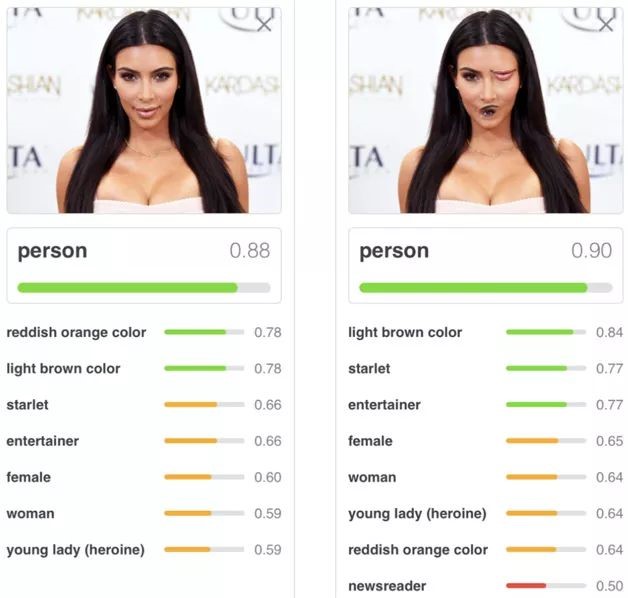
In the above picture, two portrait photos are given, and the category of the photo and its corresponding probability are given by CNN. The first photo is a normal face photo. CNN can correctly identify the category of “human” and give a attribution probability value of 0.88. The second picture adjusts the mouth and eyes of the face to the next position. For people, it is not considered to be a normal person’s face, but CNN still recognizes human beings and the confidence level does not decrease to 0.90. Why is this happening that is inconsistent with human intuition? This responsibility lies in MaxPooling, which only responds to one of the strongest features. As for where this feature appears and what kind of reasonable combination relationship should be maintained between features, it does not care, so it does not conform to human cognition. critical result.
In Capsule’s scenario, CNN’s convolutional layer is preserved and the MaxPooling layer is removed. What needs to be emphasized here is that Capsule itself is a technical framework, not just a specific technology. The Hinton paper gives the simplest implementation method, which can completely create a new one under the technical idea. The specific implementation method.
CTR Estimate: Technology upgrades to deep learning
As a technical direction of biased application, CTR is one of the most important and most concerned directions for Internet companies. At present, most of the profits of large Internet companies come from this, because this is the most important technical means to calculate advertising direction. From the perspective of computing advertisements, the so-called CTR estimate is that for a given user User, if a certain advertisement or product Product is displayed to the user under a specific context Context, it is estimated whether the user will click on the advertisement or whether to purchase a certain Products, that is, click probability P(Click per User, Product, Context). It can be seen that this is a wide-ranging technology, and many recommended scenarios and including the current hot stream sorting can be converted into CTR estimation problems.
In addition to the earlier Wide&Deep models, there have been some new deep CTR models in recent years, such as DeepFM, DeepCross, and NFM models. These models, if carefully analyzed, will find that they have great similarities in the network structure. The mainstream features are the combination of low-dimensional feature combination and high-dimensional features on the network structure. The Deep network reflects the combination of high-dimensional features, and the neural network version of the FM model is introduced to model the two-two feature combination. In summary, these three network structures basically cover all current deep CTR models.
Computer vision: a period of steady development
Computer vision is one of the most important research directions in the AI field. It itself contains many research sub-areas, including object classification and recognition, target detection and tracking, semantic segmentation, 3D reconstruction and other basic directions, as well as super-resolution. Image video description, image coloring, style migration, etc. In the current mainstream technology of computer vision processing, deep learning has occupied an absolute dominant position.
For basic research fields such as object recognition, target detection and semantic segmentation, Faster R-CNN, SSD, YOLO and other technologies are still the most advanced and mainstream technologies in the industry. Currently MaskX R-CNN recognizes more than 3,000 categories of objects, while YOLO 9000 recognizes more than 9,000 object categories. Obviously, target detection needs to be used on a large scale in various real-world fields. In addition to high speed and accurate recognition, it is also crucial to be able to identify a wide variety of object categories in various real life.
NLP: Progress is relatively slow, and technological breakthroughs are urgently needed
Natural language processing is also one of the important directions of artificial intelligence. In recent years, deep learning has basically penetrated into various sub-fields of natural language processing and made some progress, but with deep learning in the fields of image, video, audio, speech recognition, etc. Compared with the strong progress achieved, the technical dividends brought by deep learning to natural language processing are relatively limited. Compared with traditional methods, the effect has not achieved an overwhelming advantage. The reason for this phenomenon is actually a question worthy of further discussion. There are different opinions on the reasons, but there is no particularly convincing explanation that can be accepted by most people.
Deep learning in the field of natural language processing has several trends worthy of attention:
- First, the integration of unsupervised models with Sequence to Sequence tasks is an important development and direction.
- Secondly, it is a promising direction to enhance learning and how GAN and other popular technologies in the past two years have combined with NLP and really played a role.
- Again, the Attention Attention mechanism is further widely used and introduces more variants, such as Self Attention and Hierarchy Attention.
- Finally, the interpretability of neural networks is also a research hotspot, but this is not only limited to the NLP field, but also a research trend that is of great concern throughout the depth learning field.
Conclusion
This article selects some of the latest advances in the field of artificial technology, and it is inevitable that the author’s ability and the limitations of the main areas of concern will be missed. Many important technical advances are not listed in the paper. For example, the rapid development of AI chip technology represented by Google’s push of TPU, so that the machine automatically learns to design the neural network structure as the representative of “learning everything”, and the interpretation of the neural network black box problem is not explained in this article.















