
Introduction of Computer Vision Machine Learning development
by Ready For AI · October 23, 2018
The computer vision machine learning is an important application of AI in vision. In fact, this development process is not as easy as you think.

Computer vision before machine learning
Today’s Internet giants value machine learning so much, of course not for the academic value mainly because it can bring great commercial value. So why did traditional algorithms not achieve the precision of deep learning before?
Before the deep learning algorithm, for the visual algorithm, it can be roughly divided into five steps: Feature Perception, Image Preprocessing, Feature Extraction, Feature Selection, Inference Prediction and Recognition.
Among the early dominant statistical machine learning projects, they were less concerned with the feature parts. So computer vision has to design the first four parts when using these machine learning methods, which is a difficult task for anyone. The traditional computer image recognition method separates the feature extraction and the classifier design, then merges them together in the application. For example, if the input is a motorcycle image, there must first be a feature expression or feature extraction process, and then put the expressed features into the learning algorithm for classification learning.
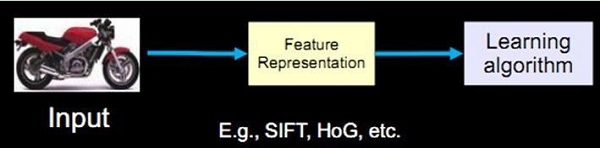
There have been many excellent feature operators in the past 20 years, such as the most famous Scale Invariant Feature Transform (SIFT) operator, which is based on scale space and maintains invariance to image scaling, rotation, and even affine transformation. SIFT extracts the local features of the image, finds the extreme points in the scale space and extracts the position, scale and direction information. SIFT’s applications include object recognition, robot map perception and navigation, effect stitching, 3D model building, gesture recognition, and effect tracking.
Another well-known is the Histograms of Oriented Gradients (HOG) operator, which calculates the human body features by calculating the gradient direction histogram on the local area, which can well describe the human body’s edges. It is not sensitive to changes in illumination and small amounts of offset. Other operators include Textons, Spin image, RIFT, and GLOH, all of which dominate the mainstream of visual algorithms before the birth of deep learning or the real popularity of deep learning.
Examples of early computer vision applications
These features and some specific classifier combinations have yielded some successful or semi-successful examples that have basically met the requirements of commercialization but have not yet been fully commercialized.
- The first is the fingerprint recognition algorithm of the 1980s and 1990s, and it is very mature. It usually searches for key points on the fingerprint pattern, looks for points with special geometric features, and then compares the key points of the two fingerprints to determine if it matches.
- Then came the Haar-based face detection algorithm in 2001, which was able to achieve real-time face detection under the hardware conditions at the time. Today the face detection in all mobile phone cameras is based on it or its variants.
- Finally, object detection based on HoG features, combined with the corresponding SVM classifier is the famous DPM algorithm. The DPM algorithm surpasses all algorithms in object detection and has achieved good results.
There are very few successful examples because manual design features require a lot of experience. You need to know a lot about this field and data, and then design features that require a lot of debugging work. To put it straightforwardly, it means that it requires a bit of luck. In addition, you not only need to manually design features but also have a suitable classifier algorithm based on this. Simultaneously designing features and then selecting a classifier to combine the two to achieve optimal results is almost a difficult task to complete.
Inspiration from bionics
If you don’t design the features manually and don’t pick the classifier, is there any other solution? Can you learn features and classifiers at the same time? That means when you input a certain model, the input is just a picture, and the output is its own label. For example, if you enter a celebrity’s avatar, the resulting label is a 50-dimensional vector – if you want to identify it in 50 people, the corresponding celebrity’s vector is 1, and the other positions are 0.
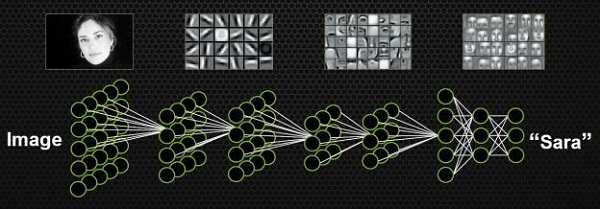
This setting is precisely the result of research in human brain science. The Nobel Prize in Medical Physiology in 1981 was awarded to a neurobiologist David Hubel, his main research results were discovered the visual system information processing mechanism, which proves that the visual cortex of the brain is hierarchical. He believes that human visual function is abstraction and iteration. Abstraction abstracts the elements of a very specific image into a meaningful concept, then these meaningful concepts will be iterated upwards and become abstractions that are more abstract and human-perceived.
Although the pixels themselves have no abstract meaning, the human brain can connect these pixels into edges, and the edges become a more abstract concept with respect to pixels. The human brain processes the edges to form a graph, and then abstracts the graph into concrete objects, so the brain finally knows what it sees.
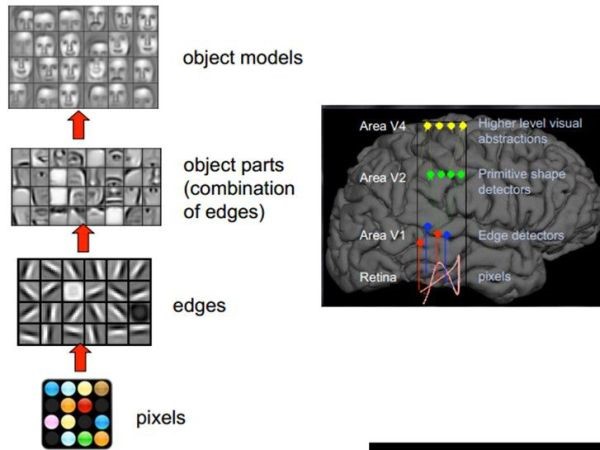
Simultaneously simulating the human brain to recognize faces is also an abstract iterative process, from the first pixel to the edge of the second layer to the part of the face, and then to the entire face is a complete abstract iterative process.
The so-called feature or visual feature is to combine these values in the statistical or non-statistical form. Before the popularity of deep learning, most of the design image features were based on this, that is the pixel-level information in an area was comprehensively expressed for later classification learning. If we want to fully simulate the human brain, we need to simulate the process of abstraction and recursive iteration, abstracting the information from the most subtle pixel level to the concept of “category” for the computer to accept and learn.
Convolutional Neural Network concept
Convolutional Neural Networks (CNN) are often used in computer vision as a more accurate simulation of the human brain. Convolution is to confirm the relationship between two functions and then generate a new value, which is the process of doing integral calculations in continuous space and then summing them in discrete space. In fact, in computer vision convolution can be regarded as an abstract process, which is to abstract the information in a small area.
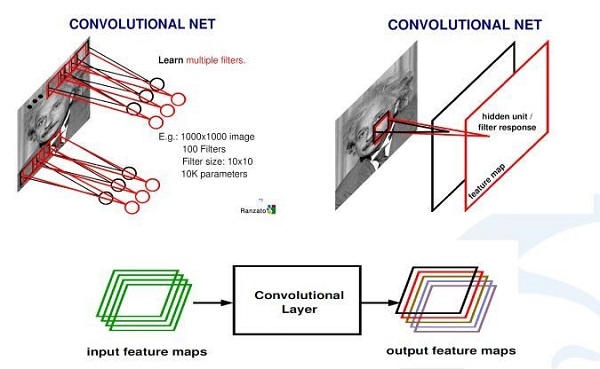
The above diagram describes how to get from the input image to the final convolution and the generated response map. First, the learned convolution and the image are scanned, and then each convolution sum generates a scanned response map or feature map. If there are multiple convolution sums, there are multiple feature maps. That is to say, from an input image (RGB three channels) with 256 channel feature maps can be obtained, each convolution and representing a statistical abstraction.
In addition to the convolutional layer in the Convolutional Neural Network, there is also a pooling operation. The statistical concept of pooling operations is more explicit, that is, statistical operations for averaging or maximizing a small area. The result of this processing is that if I input two channel, or 256 channel convolution response feature map, each feature map goes through a pooling layer that is the largest, which will get a 256 channel feature map smaller than the original feature map.
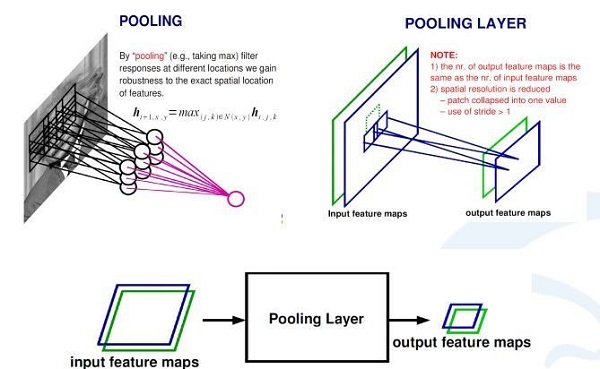
In the above example, the pooling layer maximizes each 2*2 region and assigns the maximum value to the corresponding location of the generated feature map. If the input image is 100*100, the output image will become 50*50. At this time, the feature map becomes half of the original, and the retained information is the largest information in the original 2*2 area.
Original prototype: LeNet network
Le in LeNet refers to Yann Lecun, an expert in artificial intelligence, which was the original prototype of a deep learning network. LeNet was invented in 1998 when Lecun was at AT&T’s lab, and he used this network for letter recognition to achieve very good results.
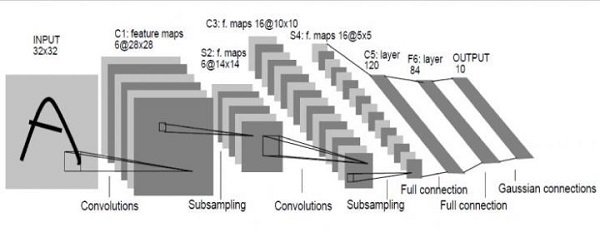
How is it formed? The input image is a 32*32 grayscale image. The first layer passes through a set of convolution sums to generate six 28*28 feature maps, and then passes through a pooling layer to get six 14X14 feature maps. After a convolutional layer, sixteen 10*10 convolutional layers are generated, and sixteen 5*5 feature maps are generated through the pooling layer.
Starting with the last sixteen 5*5 feature maps, after three fully connected layers reach the final output, this output is the output of the label space. Since the design is to identify 0 to 9, the output space is 10. If you want to identify ten numbers plus twenty-six letters, the output space is 62. In a 62-dimensional vector, if the value in a dimension is the largest, the letter and number corresponding to it are the prediction results.
The key point to reverse the situation
In the 15 years from 1998 to the beginning of this century, the results of deep learning have been few, and even this technology has been marginalized. Until the advent of AlexNet in 2012, the deep learning algorithm began to achieve good results in some areas.
AlexNet was developed by several scientists at the University of Toronto and surpassed all shallow learning methods in the ImageNet competition. Since then, everyone has come to realize that the era of deep learning has finally arrived, and some people use AlexNet for other application development, while others have begun to develop new network structures.
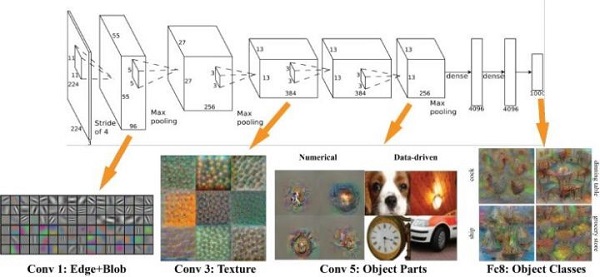
In fact, the structure of AlexNet is also very simple, it is just an enlarged version of LeNet. The input is a 224*224 image, after several convolutional layers and several pooling layers, and finally connected to the two fully connected layers to reach the final label space. In the first layer are some features such as filled blocks and boundaries; the middle layer begins to learn some texture features; higher layer close to the level of the classifier, the characteristics of the object shape can be clearly seen; the last layer classified Layers are showing different poses according to different objects.
It can be said that whether it is to identify faces, vehicles, elephants or chairs, the first thing to learn is the edge, and then the part of the object, and then at a higher level can be abstracted to the whole of the object. The entire Convolutional Neural Network just simulates the process of human abstraction and iteration.

Some people may ask: Convolutional Neural Network design is not very complicated, and in 1998 there has been a relatively decent prototype. Then why is the Convolutional Neural Network occupying the mainstream after 20 years?
In my opinion, this problem is not too much related to the technology of the Convolutional Neural Network itself, but related to other objective factors.
- The first is image data. If the depth of the Convolutional Neural Network is too shallow, the recognition ability is often inferior to the general shallow model, such as SVM or boosting. But if you do it deeply, you need a lot of data to train, otherwise the over-fitting in machine learning will be inevitable. Until the popularity of the Internet that is able to generate a large variety of image data for the algorithm to learn.
- The second is computing power. The Convolutional Neural Network requires relatively high computational requirements for computers. It requires a large number of repetitive parallelization calculations. In the case where the CPU has only a single core and the computing power is relatively low, it is impossible to train a deep Convolutional Neural Network. As GPU computing power grows, Convolutional Neural Networks combined with big data training become possible.















